The Latest from TechCrunch |  |

- DoubleTwist’s New Alarm Clock For Android Wakes You With Your DoubleTwist Tunes
- (Founder Stories) Kayak’s Paul English Discusses Big Wins & Important Strategic Alliances [TCTV]
- Skolkovo: Cisco, Bessemer Venture Partners Put Millions Into Russia’s Latest Answer To Silicon Valley
- Social, Mobile Video Sharing App Klip Doubles Down On Visual Effects In New Version
- It’s A Disney Party! DeNA & Disney Team Up To Launch Mobile Games Worldwide
- New Google Drive Leak Points To 5GB Of Free Storage, Release In Third Week Of April
- Jordan Mechner, Creator Of Prince Of Persia, Finds Original Source Code In His Dad’s Closet
- Plukka Founder Joanne Ooi On Merging Manufacturing And Group Buying
- Sources Say Richard Branson Has Joined Dave Morin’s Slow Ventures [Updated]
- Amid UDID Uncertainty, AppRedeem Creates New ID Scheme, Groupon Adopts
- Wikipedia’s Next Big Thing: Wikidata, A Machine-Readable, User-Editable Database Funded By Google, Paul Allen And Others
- The Ground Beneath Apple’s Walled Garden
- Israeli-American Accelerator UpWest Labs Graduates Its First Batch Of Startups
- Best Buy To Shut 50 Stores In Streamlining Effort
- Patients Are More Than A Vessel For Billing Codes
- Kickstarter Shares The Effects Of Its Blockbuster Season
- Confirmed: LivingSocial Co-founder Eddie Frederick Steps Down From Leadership, Board
- The Cloud Will Cure Cancer
- WSJ: Google Planning To Sell Tablets Straight To Consumers
- Algorithmic Essay-Grading: Teacher’s Savior Or Bane Of Learning?
| DoubleTwist’s New Alarm Clock For Android Wakes You With Your DoubleTwist Tunes Posted: 30 Mar 2012 09:23 AM PDT  DoubleTwist, the maker of the popular suite of applications for syncing music and media between devices, has just surprised its users with the release of a new application today. And this time, the app branches out from the company’s prior focus on media management – it’s an alarm clock app for Android phones. But on closer inspection, DoubleTwist Alarm actually does makes sense as an extension of the DoubleTwist brand, as the app is designed to wake you with music. In fact, it even connects with the company’s mobile Player app, allowing you to configure songs or entire playlists as the music you wake to. The Android-only app has an attractive interface with big, bold numbers, and a number of expected features including the option to switch between analog and digital interfaces, support for multiple and recurring alarms, custom labels, and a built-in selection of alarm sounds to choose from. DoubleTwist users can also set up the app to work with the music they have in the Player app, if they choose. There’s another nifty feature too: something called “SleepCycle,” which will suggest a handful times you can wake up that correspond to full sleep cycles. By doing so, the idea is that you’ll wake up feeling more refreshed. Of course, since the app doesn’t actually know when you fall asleep, that functionality is going to be hit-or-miss in terms of results. But it’s kind of a cute thing to add. The app costs 99 cents during its launch day special, but will double in price after the first 10,000 users. You can grab it from Google Play here.
      |
| (Founder Stories) Kayak’s Paul English Discusses Big Wins & Important Strategic Alliances [TCTV] Posted: 30 Mar 2012 07:38 AM PDT  Having recently posted its 2011 revenue numbers, Kayak.com’s co-founder, Paul English stopped by TCTV to tape an episode of Founder Stories with host Chris Dixon. In part I of this conversation, English describes serendipitously meeting co-founder Steve Hafner (who previously co-founded Orbitz), speaks to the importance of striking the right business partnerships and offers insights into how Kayak tests its products. English says Kayak’s origins date back to 2003 when he was introduced to his co-founder Steve Hafner through a mutual contact. He tells Dixon the two immediately hit it off, went to a bar and “an hour later decided each to throw a bunch of money in” to start Kayak. English and Hafner then put together a board that included ”the original founders of Expedia and Travelocity.” English notes this leadership offered Kayak additional legitimacy in the eyes of the industry, as did the opportunity to “take over travel search for the AOL portal.” And says the AOL deal “got us a lot of attention because … we had an anchor tenant with a lot of traffic.” Speaking further to the AOL partnership, English tells Dixon, “It is hard to get those deals but it is a huge emotional win and PR win for the industry. I think to tell people that you are an unknown startup, but you are powering … travel management for some big company, it gives you cred that allows you to then ask for other things, so I think it was really key to us in 2004.” Make sure to watch the entire interview to hear additional insights, and be on the lookout for part II of this interview which is coming up. Past episodes of Founder Stories featuring leaders of FindTheBest, Kiva Systems, TripAdvisor, Warby Parker, ZocDoc and many other companies are here.
  |
| Posted: 30 Mar 2012 07:06 AM PDT  In the debate over whether there can ever exist “another Silicon Valley” and where, exactly, it would be, add in another contender: Skolkovo, an ambitious high-tech sprawl being built outside of Moscow, which this week announced the latest two companies to invest in its big idea: Cisco and Bessemer Venture Partners. Bessemer has promised investments worth $20 million over the next two years into startups that are resident at Skolkovo, while Cisco has dedicated an unspecified part of a $1 billion injection it is making into Russia over a number of years to build an R&D lab in the area — part of big push from the government to take some of the technology know-how that Russia has been producing for decades and give it a significantly more commercial spin. The Bessemer investment means that there are now more than 30 VCs that have committed to putting money into Skolkovo-startups. (One happens to also include Cisco, working with Russian VC Almaz.) As a result of the agreement, Bessemer will get “priority access” to the Skolkovo Foundation project pipeline (not clear whether that will be over and above access by other VCs). It will focus on seed and Series A investments; and it will be able to potentially bring some of its own portfolio companies into Skolkovo. Its portfolio companies include the cloud-services company Parallels and group-buying club KupiVIP. (Being resident at Skolkovo, which you get after applying and being accepted by the foundation, gives a startup financial support in the form of possible grants, but also a place to work and operational support.) Just as Bessemer is joining a group of VCs, Cisco is not the first big IT company to pump money into the Russian tech ecosystem. HP has its HP Lab near St. Petersburg, and IBM, Nokia, Siemens and around 100 others have all signed up to invest in Skolkovo’s IT cluster (other clusters include biomedicine, energy, space technology and nuclear technology). It’s still early days, so Cisco’s aims are suitably ambitious in their scope at this point: “Cisco aims to focus R&D in Skolkovo on high-impact areas of the business, including video and internal start-ups, using Skolkovo as the physical and virtual platform for innovation,” Cisco says. “This will contribute to transforming Skolkovo into one of the most advanced technology regions in the world.” Specifically the investment that Cisco has now committed will be used to build out a center on the Skolkovo campus and run an R&D operation there, as well as continued funding for training and education programs. That speaks to another point: since Skolkovo was announced in 2010, not a whole lot has come out of it in terms of actual product while the building of it gets underway. Even so, people seem mostly positive that projects like this are the right step forward to improve the IT and tech economy in the country. That’s because before Skolkovo, Russia didn’t have much in the way of an R&D environment as it exists in a place like Silicon Valley: in a throwback to Soviet days, R&D had been based on institutes and had “no commercial element,” said a spokesperson for Russian search giant Yandex. And at the same time, a lot of investment money and talent has been exported abroad, whether in the form of investments in Facebook, or Russian engineers contracted to work for startups elsewhere. Some worry that having the government back the effort with millions of state money makes it potentially less stable: “As long as Skolkovo is supported by the government, it is viable,” one founder told me. “What if government changes its mind, or if there is a budget deficit?” Others see the entry of all these international companies, like Cisco and Bessemer, as a route to leveraging that risk. “Yes, Skolkovo is pretty ambitious, and there is some political coloring because of the connection to [Russia's President] Dmitry Medvedev, but now he’s moving this into the hands of private businesses, and that’s the right decision,” said the Yandex spokesperson. “Sooner or later those businesses will ask for an ROI.” Yandex, it should be pointed out, is one of the many other routes to getting funding and building out tech companies. It doesn’t have any involvement with Skolkovo itself but it has its own R&D operation as well as its own incubator, Yandex.factory. Its latest investment was a seed round in Israel-based GBooking, focused on IT services for small businesses.
  |
| Social, Mobile Video Sharing App Klip Doubles Down On Visual Effects In New Version Posted: 30 Mar 2012 07:05 AM PDT  Klip, a mobile app that allows users to capture, share, discover and view videos, is debuting a new version of its iOS app that allows users to shoot videos with visual effects and filters in real-time. The company has also added seven new video effects to the app. Klip, which launched in September, is focused on mobile video discovery and providing the highest quality video streaming around for iOS. You simply shoot a new ‘Klip’ or grab one from your Camera Roll and share it with the community, your friends on Facebook, Twitter, on your YouTube channel, or by email. Within the app, you can watch Klips from around the world, follow other Klippers, re-klip the Klips you think are worth sharing again, or stay on top of hot topics by following hashtags. As Klip explains to me, shooting a mobile video with the effects on in real-time (as opposed to adding the effects afterwards) is a complex computer science challenge. The new effects added to the app include, Zenith (a retro tube TV effect in both color and black & white), a cartoon-like effect (Toon), Gotham, Cinema (an old time movie effect), HDR, Fisheye (mirror effect) and Voodoo. Klip is particularly proud of this effect, which highlights one color (green or red) and displays all other colors as black and white. Klip has been steadily updating its app since launch last year, most recently adding suggested recommendations, and SMS functionality. And the startup just raised $8 million in Series B funding from Benchmark Capital, Matrix Partners and Alain Rossmann (the founder of the company).
  |
| It’s A Disney Party! DeNA & Disney Team Up To Launch Mobile Games Worldwide Posted: 30 Mar 2012 07:03 AM PDT  Disney and Japanese mobile gaming giant DeNA announced a new partnership this morning that will see their first jointly developed mobile social games launched on DeNA’s Mobage social gaming platform, beginning later this month. The first title to arrive, “Disney Party,” was released on March 28th to the Mobage network in Japan, which serves a mobile gaming audience of over 35 million. On April 2nd, a second title will arrive in Japan called “Disney Fantasy Quest.” These two games will involve Disney’s own characters, but will be followed by a third, (yet to be named) card game battle that’s based on Marvel Comics characters. The two companies aren’t only focused on Japan, despite DeNA’s Japanese roots – the plan is to make all three titles available worldwide. Localized versions of the two games will arrive both as smartphone apps as well as on Mobage’s non-Japanese networks: Mobage Global for North America and Europe, Mobage China, and Daum Mobage for South Korea. They will be the first three jointly developed titles released outside of Japan. In addition, the new agreement will also see Disney and DeNA teaming up on other efforts, including Disney movies, Disney TV shows and smartphone apps. Disney Japan’s president said at a news conference that he hoped the unnamed Marvel Comics game would help raise awareness in Japan where the characters don’t have a built-in audience, ahead of the film which opens in August. (The Avengers, perhaps?) DeNA has been doing well as of late. The company posted a strong third quarter in February, which saw net sales up by 16%, boosting its valuation to $4.8 billion. It’s now working on building up its presence in the U.S., Europe, China and South Korea – and this Disney deal will certainly help.
  |
| New Google Drive Leak Points To 5GB Of Free Storage, Release In Third Week Of April Posted: 30 Mar 2012 06:49 AM PDT  Evidence of Google Drive’s existence has been sporadically surfacing for months now, and MG reported last September that Google employees have been using the reborn service in-house for a while now. Now, as the service’s supposed launch draws ever closer, we’re starting to get our first clear glimpses at what Google’s had under lock and key for so long. According to a leaked screenshot obtained by TalkAndroid, Google Drive could offer even more functionality than earlier reports suggested — if legitimate, then Google Drive users could have access to 5GB of free storage right out of the gate. Their mysterious source also confirmed to them that the service is on track for an official launch during the week of April 16. It seems like a smart move that would best Dropbox’s 2GB of free storage and put Google on even footing with Amazon’s Cloud Drive (Microsoft leads the pack with 25GB of free storage in SkyDrive.) Still, the leak raises a big question — who’s actually got the story right? TalkAndroid’s source sent them another screenshot earlier in the week depicting the Google Drive Windows client in action, and it specifically points out that users have access to 2GB of free storage (though they can “always buy more,” a phrase which reappears in this latest leak). What’s more, the logo depicted in that older screenshot appears to be the same one spotted by GeekWire in February, but this newest screenshot uses a slightly tweaked version that drops the red in favor of green. Is this the sign of a clever fake, or a last-minute rebranding effort on Google’s part? Meanwhile, Om Malik seemed awfully confident when he reported earlier this week that Google Drive is poised to launch at some point during the first week of April, with Google offering their users only 1GB of free storage. His sources seemed to confirm the notion that truly voracious users can purchase more cloud storage from Google, though Malik’s sources wouldn’t go details like pricing and storage tiers. It’s obvious that Google Drive is coming, and coming soon, but Google’s going to be playing their last few cards as close to their collective chests as they can. Still, with April fast approaching, I suspect the full story will be unearthed sooner rather than later. Update: TalkAndroid’s source says that the service will launch during the week of the 16th, not necessarily on that day. I’ve changed the headline to reflect this.
 |
| Jordan Mechner, Creator Of Prince Of Persia, Finds Original Source Code In His Dad’s Closet Posted: 30 Mar 2012 06:24 AM PDT  Prince of Persia and Karateka, were two of the best action games of their era. Why? Because they gave us an inkling of what real, fluid graphical motion would look like in a few years’ time and, more important, were pretty much amazing if you were used to the Atari 2600 and River Raid. I remember playing Karateka before school at age ten, chopping my way through enemies on my way to save my sweetie and then, a few years later, playing PoP. Both were amazing. Why? Because he created smooth, believable animation at eight frames per second on machines that were more suited to games like The Oregon Trail. He also created action games that led to realistic titles like Tekken that used real, human motion in order to add amazing realism. A funny thing happened about ten years ago. The creator of these games, Jordan Mechner, apparently lost the original PoP source code and hunted all over for it, asking former Broderbund employees and digging through old files. The files – stored on 3.5-inch floppy disks – contained the original machine code for the game. The only way to actually play the game, until today, was to run an emulated, extracted ROM. Mechner, however, just received a box from his Dad. In it were a few Amstrad cassettes of his games and, more important, the original Apple II source code. That’s right: PoP will be back in its original form as soon as Mechner figures out how to pull data off of the ancient disks and handle the 6502 processor code. Says Mechner: So, for all fifteen of you 6502 assembly-language coders out there who might care… including the hardy soul who ported POP to the Commodore 64 from an Apple II memory dump… I will now begin working with a digital-archeology-minded friend to attempt to figure out how to transfer 3.5″ Apple ProDOS disks onto a MacBook Air and into some kind of 21st-century-readable format. (Yuri Lowenthal, you can guess who I'm talking about.) In short, it looks like PoP is back. This is a great day for 1980s motion-cap action/martial arts/run and jump games.
  |
| Plukka Founder Joanne Ooi On Merging Manufacturing And Group Buying Posted: 30 Mar 2012 06:08 AM PDT  We’ve seen a lot of group buying services cross the home page here at TechCrunch, and almost all of them have one thing in common: they sell you the stuff that has been marked down, and couldn’t be sold at the time intended. But a new startup called Plukka, an e-commerce site focused on high-end designer jewelry, is going in an entirely different direction when it comes to group buying. I had the opportunity to sit down with founder Joanne Ooi, who stressed that the most important part of the Plukka equation is something she refers to as “just-in-time” manufacturing. Here’s how it works: You hop on over to Plukka.com and browse through their listings of various jewelry items. When you’ve found what you want, you add the item to your cart and even though your credit card is blocked for the original amount, the transaction only goes through after the final amount has been calculated. See, prices on the jewelry at Plukka slowly go down as more and more people want to buy it. It becomes available on the site for one or two days, and if even one person wants to buy it, Plukka will make it. The time period also extends to allow for more potential buyers, and the more people who purchase, the more the price drops. At the end of the event, the final low price is the same for everyone, whether you were the first to buy or the last. Right now the service is run on an event-by-event basis, but in April Plukka is introducing an entire product catalog so that new customers will have more variety to choose from. I know it can be a bit confusing, but a really helpful explanation can be found in the video below.
  |
| Sources Say Richard Branson Has Joined Dave Morin’s Slow Ventures [Updated] Posted: 30 Mar 2012 05:35 AM PDT  Amen, the ‘strong opinions’ app that’s making waves and has high profile investors like Ashton Kutcher, released a new version of its iPhone app this week. It’s staying deliciously simple but Version 1.5 of the app added some long needed new features. It also took in a fresh $1m (taking its total pot to $2.9m) from Sunstone Capital and Path's Dave Morin, came on board as an angel investor via his vehicle Slow Ventures. But we understand that Amen may well take in a new investor who you might have heard of: noted global entrepreneur, Sir Richard Branson. We have also heard from well placed sources that Branson is a silent partner in Slow Ventures with Morin. We’ve reached out to them for comment. [Update: Dave Morin has told us that this is latter part is "not even remotely true."] Amen cofounder Caitlin Winner recently pitched to Branson on his private island as is evidenced by a post on Amen by CEO Felix Peterson and on Winner’s site and Twitter. We’ve confirmed this via sources. This is pretty interesting news for technology startups. Branson is an icon of entrepreneurship in the UK because of the success of his Virgin brand and known globally for his airline and space ventures. Amen, where you air a strong opinion about something (something is ‘the best’ or the ‘worst thing ever’). You can now add pictures to posts, the ability to listen to a 30-second preview of an iTunes song and buy it, commenting, Facebook timeline and contact support, CEO Felix Peterson says that Amen is getting "industry leading retention and activity numbers." The other investors in Amen are Index (Danny Rimer); A Grade (Ashton Kutcher, Ron Burkle, Guy Oseary); Christophe Maire, and SoundCloud founders Alexander Ljung and Eric Wahlforss.
  |
| Amid UDID Uncertainty, AppRedeem Creates New ID Scheme, Groupon Adopts Posted: 30 Mar 2012 05:21 AM PDT  Six months ago, Apple began making some big changes to its operating system ahead of the release of iOS5. Among them, was the news that it would begin ramping up the deprecation of the UDID — Apple’s go-to identifier that ties users to their specific iOS device. The company remained silent for months, but, as Kim-Mai reported last week, Apple recently began to take action, and is now rejecting apps that attempt to access those identifiers. Naturally, this has the iOS developer community sounding the alarm bells. Even though Apple made its intentions known months ago, since then, there’s been no consensus among developers as to the best replacement. Some have perhaps expected Apple to propose a solution, but the company has remained silent. Apps that access UDIDs are still making it into the App Store, but developers now have to disclose the fact that they’re using them, and ask users for permission. Because of the mounting privacy concerns (from Congress, etc.), Apple is going to nix UDIDs altogether, but it remains unclear how long that will take. In the meantime, developers are scrambling to find alternatives, and Kim-Mai yesterday laid out some of the options available to those looking to take preemptive action. Of the choices, MoPub thinks the best near-term solution is the open source project, OpenUDID. Crashlytics has proposed another variation, SecureUDID. Whatever the solution, there’s no question that the UDID issue has big potential ramifications for mobile advertising, as Amit Runchal pointed out. Developers and mobile ad companies unilaterally need to find a workable solution, and yesterday we caught up with Sheffield Nolan, the Co-founder of AppRedeem, whose team has developed its own alternative to UDIDs with what it’s calling the “Organizational Specific Device Identifier” (ODID). Nolan says that, while Apple is backing off a bit on UDIDs in the short term with opt-in requirements, it’s really just postponing the inevitable. The “universal” part of UDID will end, and a replacement is imperative so that developers can switch before the next scare. The CEO tells us that the AppRedeem, which, for those unfamiliar, is an advertising platform designed to help developers boost engagement and drive new users to their mobile apps, tried a bunch of options, including fingerprinting, but they were found lacking. Really, any solution predicated on having a global identifier for the device still doesn’t address the real privacy issues, he said, so the team began working on hashing Mac addresses. They did this for about six months, until they realized that, without the ID being bound to an organization, again, users would experience the same privacy concerns inherent to the UDID. So, the team created ODID as a way to address user privacy issues. Over-simplifying, an ODID is created by appending a hash of the MAC address to an organization’s “secret key” to create the payload, and then applying a hash wrapper to the payload. Furthermore, the ODID is sandboxed within the specific organization that created it, and the device’s Mac address is used as the seed for the ODID. This is the key: There’s no way to derive the MAC address from an ODID, because the MAC address is only a seed, so Company A, for example, could not determine if Company B’s ODID belonged to Company A’s users — even if they had the “secret key” — while both companies still have what they need to track their own users. What’s more, the ODID does not disappear with a device reset, so individual game developers can track their users even if there’s a reset, which is really what everyone is clamoring for. Beginning on Thursday, AppRedeem began rolling out an update to its SDK with ODID support, which will be available for all customers by the weekend. The SDK is in plain source code, so everyone can see how it works, and AppRedeem is sharing the steps to create an ODID to AppRedeem’s spec so that users can do it on their own or just use its SDK. AppRedeem currently has 3.4 million members on its platform, and App Trailers, its iOS app, has been downloaded 1 million times (and is currently seeing 20K downloads a day), the CEO says. The company’s advertisers include Groupon, Zynga, Disney, TinyCo, GameLoft, Priceline, Glu, Addmirred, AOL, and Smule; all in all, Nolan says, over half of the top 100 grossing apps use AppRedeem, which means the startup had good reason to find a solution that works for everyone. Groupon is the first of its advertisers to begin using the startup’s UDID-free SDK, as they were in a rush to realize full compliance with Apple, and wanted to switch as soon possible. Although the UDID affects mobile advertisers (and mobile ad networks) most acutely, it really touches any iOS developer looking to track usage, downloads, clicks, etc. — all stuff that’s essential to mobile ad rev models. And there are a lot of those. As Amit points out, the UDID debacle really shows that the way Apple deals with its apps isn’t just going to affect individual business models, it has implications for the way an entire industry operates. Apple likely never intended the UDID to become so vital to the economy they created, but it has. Most companies with iOS apps are scrambling to find a solution, and Nolan says that they’ve been in talks with TinyCo, Zynga, GameLoft, and that the majority of companies he’s talked to, both big and small, are trying to find a workaround. Any mobile business that has as its priorities both consumer privacy and advertisers tracking needs a better alternative to UDID. Nolan says that he hasn’t seen anyone really taking the lead, so the team has pushed to turn ODID into a replacement scheme for UDIDs — in such a way that doesn’t just solve the problem for their own clients, but offers a model for all businesses looking for better privacy tools for their users. The startup is currently in the process of pushing its SDK live, and is in the process of creating a landing page and docs, which the AppRedeem CEO says should be live on the homepage soon. We’ll include a link when it goes live. AppRedeem homepage here. What do you think?
  |
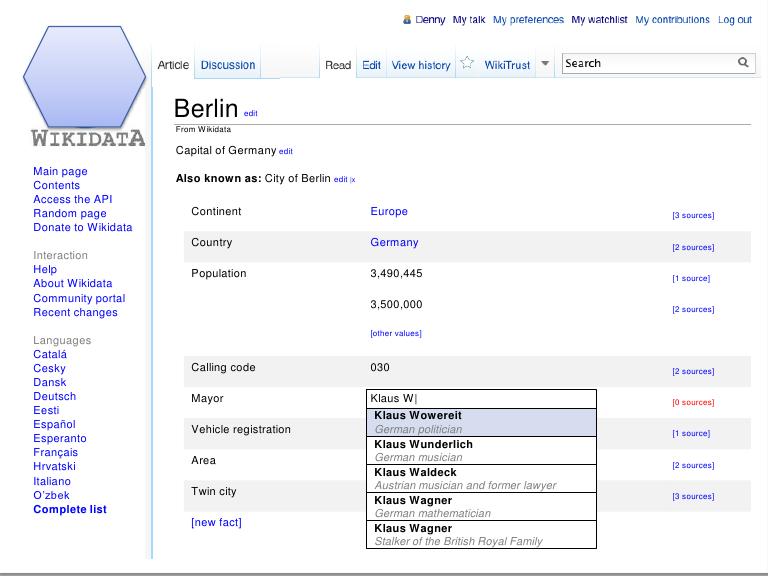
| Posted: 30 Mar 2012 03:00 AM PDT  Wikidata, the first new project to emerge from the Wikimedia Foundation since 2006, is now beginning development. The organization, known best for its user-edited encyclopedia of knowledge Wikipedia, recently announced the new project at February’s Semantic Tech & Business Conference in Berlin, describing Wikidata as new effort to provide a database of knowledge that can be read and edited by humans and machines alike. There have been other attempts at creating a semantic database built from Wikipedia’s data before – for example, DBpedia, a community effort to extract structured content from Wikipedia and make it available online. The difference is that, with Wikidata, the data won’t just be made available, it will also be made editable by anyone. The project’s goal in developing a semantic, machine-readable database doesn’t just help push the web forward, it also helps Wikipedia itself. The data will bring all the localized versions of Wikipedia on par with each other in terms of the basic facts they house. Today, the English, German, French and Dutch versions offer the most coverage, with other languages falling much further behind. Wikidata will also enable users to ask different types of questions, like which of the world’s ten largest cities have a female mayor?, for example. Queries like this are today answered by user-created Wikipedia Lists – that is, manually created structured answers. Wikidata, on the hand, will be able to create these lists automatically. The initial effort to create Wikidata is being led by the German chapter of Wikimedia, Wikimedia Deutschland, whose CEO Pavel Richter calls the project “ground-breaking,” and describes it as “the largest technical project ever undertaken by one of the 40 international Wikimedia chapters.” Much of the early experimentation which resulted in the Wikidata concept was done in Germany, which is why it’s serving as the base of operations for the new undertaking. The German Chapter will perform the initial development involved in the creation of Wikidata, but will later hand over the operation and maintenance to the Wikimedia Foundation when complete. The estimation is that hand-off will occur a year from now, in March 2013. The overall project will have three phases, the first of which involves creating one Wikidata page for each Wikipedia entry across Wikipedia’s over 280 supported languages. This will provide the online encyclopedia with one common source of structured data that can be used in all articles, no matter which language they’re in. For example, the date of someone’s birth would be recorded and maintained in one place: Wikidata. Phase one will also involve centralizing the links between the different language versions of Wikipedia. This part of the work will be finished by August 2012. In phase two, editors will be able to add and use data in Wikidata, and this will be available by December 2012. Finally, phase three will allow for the automatic creation of lists and charts based on the data in Wikidata, which can then populate the pages of Wikipedia. In terms of how Wikidata will impact Wikipedia’s user interface, the plan is for the data to live in the “info boxes” that run down the right-hand side of a Wikipedia page. (For example: those on the right side of NYC’s page). The data will be inputted at data.wikipedia.org, which will then drive the info boxes wherever they appear, across languages, and in other pages that use the same info boxes. However, because the project is just now going into development, some of these details may change. Below, an early concept for Wikidata: All the data contained in Wikidata will be published under a free Creative Commons license, which opens it up for use by any number of external applications, including e-government, the sciences and more. Dr. Denny Vrandečić, who joined Wikimedia from the Karlsruhe Institute of Technology, is leading a team of eight developers to build Wikidata, and is joined by Dr. Markus Krötzsch of the University of Oxford. Krötzsch and Vrandečić, notably, were both co-founders of the Semantic MediaWiki project, which pursued similar goals to that of Wikidata over the past few years. The initial development of Wikidata is being funded through a donation of 1.3 million Euros, granted in half by the Allen Institute for Artificial Intelligence, an organization established by Microsoft co-founder Paul Allen in 2010. The goal of the Institute is to support long-range research activities that have the potential to accelerate progress in artificial intelligence, which includes web semantics. “Wikidata will build on semantic technology that we have long supported, will accelerate the pace of scientific discovery, and will create an extraordinary new data resource for the world,” says Dr. Mark Greaves, VP of the Allen Institute. Another quarter of the funding comes from the Gordon and Betty Moore Foundation, through its Science program, and another quarter comes from Google. According to Google’s Director of Open Source, Chris DiBona, Google hopes that Wikidata will make large amounts of structured data available to “all.” (All, meaning, course, to Google itself, too.) This ties back to all those vague reports of “major changes” coming to Google’s search engine in the coming months, seemingly published far ahead of any actual news (like this), possibly in a bit of a PR push to take the focus off the growing criticism surrounding Google+…or possibly to simply tease the news by educating the public about what the “semantic web” is. Google, which stated it would be increasing its efforts at providing direct answers to common queries – like those with a specific, factual piece of data – could obviously build greatly on top of something like Wikidata. As it moves further into semantic search, it could provide details about the people, places and things its users search for. It would actually know what things are, whether birth dates, locations, distances, sizes, temperatures, etc., and also how they’re connected to other points of data. Google previously said it expects semantic search changes to impact 10% to 20% of queries. (Google declined to provide any on the record comment regarding its future plans in this area). Ironically, the results of Wikidata’s efforts may then actually mean fewer Google referrals to Wikipedia pages. Short answers could be provided by Google itself, positioned at the top of the search results. The need to click through to read full Wikipedia articles (or any articles, for that matter) would be reduced, leading Google users to spend more time on Google.
  |
| The Ground Beneath Apple’s Walled Garden Posted: 29 Mar 2012 11:30 PM PDT  Apple’s blanket rejection of apps accessing UDIDs is just the latest in a long line of erratic behavior on Apple’s part of enforcing the rules of the iOS App Store. Sure, Apple warned developers that they were deprecating UDID, but like many of Apple’s Delphic pronouncements about the iOS App Store it was a little unclear, vague and open to interpretation. Many developers assumed that they would have at least until the release of iOS 6 to clear things up, but that turned out to be too optimistic. Of course, that’s nothing new. From rejecting apps for objectionable political content to the blanket and ridiculous rejection of apps like Podcaster and MailWrangler for “duplicating functionality” but nevertheless allowing hundreds of weather apps the chance to bloom, the uncertainty facing developers has had a very real and negative effect on the iOS ecosystem. It took more than three years after the App Store opened its doors for a decent third-party mail app to be available for the iPhone. Apple seems to have loosened things up recently — or shown that they are at the very least capable of being shamed into doing the right thing — but the way they’ve handled the UDID issue shows Apple’s priorities haven’t changed: Apple über allies, followed by users and than developers. The line between the UDID-poclaypse and the Path mini-debacle is pretty clear. This is Apple protecting its back. But it also shows just how endemic the risk is of building a business in the App Store. Their treatment of UDID shows how Apple’s treatment of apps has the ability to not just impact an individual company’s business model but the way entire industries function. There are already alternatives to UDID being shopped around right now, but it’s not clear that Apple won’t put the hammer down on those as well. Apple may allow third-party systems or even tracking MAC addresses. But at the end of the day Apple’s not cracking down on implementation schemes. They’re cracking down on tracking, period. Methods be damned. While there are many non-creepy uses of UDID, obviously this has the potential to most seriously affect the mobile advertising industry. Advertisers believe there’s a huge potential to deliver more valuable ads based on behavioral and geographic targeting, and Apple threw a spanner in the works. The size of that spanner is yet to be determined. While it’s easy to argue that Apple should implement consistent standards on how they deal with changes to rules in the iOS App Store, that’s easier said than done. Apple themselves don’t seem to know the rules of the App Store right now or how they’re going to change. Their approach is entirely “I know it when I see it.” Though each iOS development cycle sees the opportunity for the creation of new business models, it also brings a new round of uncertainty as Apple figures out what, exactly, they’ve unleashed. Imagine this scenario. Recently Highlight and other recent location-aware social networking apps have gotten dinged for battery issues. Constant, continual broadcasting of background data was probably not what Apple imagined when they opened up backgrounding in iOS 4, but some clever hackers saw a use for it, and lo — an evolution in social networking. But what if this battery issue became a serious public relations problem? Or what if it’s worse? What if unscrupulous developers used the background data for a more nefarious purpose? It’s not hard to imagine the New York Times coverage or the questioning letters from government officials. They can probably just copy and paste from the last one: “This incident raises questions about whether Apple's iOS app developer policies and practices may fall short when it comes to protecting the information of iPhone users and their contacts.” How does Apple react? By rejecting apps like Highlight or changing their backgrounding rules. Millions of venture capital dollars are suddenly backing companies that just became the walking dead. This is all because this became Apple’s fault— again. As has every other issue raised by anything tangentially related to Apple has become. People blamed Path, sure, but they also blamed Apple. Did Apple do anything wrong in the Path case? Debatable, but the key point is that Apple allowed it to happen. How possible is it that the next decade or so continues like this in the App Store? That the constant push-pull cycle between Apple and developers continues unabated? Apple is clearly being pressured to react swiftly without a lot of time to consult developers. How does sticking to a bureaucratic timeline work when government officials smell blood in the water? Apple is going to be under constant scrutiny by the press and the U.S. government for as long as they’re enormously successful, and there’s no sign that their success will be abating any time soon. As long as that’s the mentality surrounding Apple, developers will keep taking hits, especially those relying on advertising or tracking to provide future revenues. And if you think Apple is very concerned about advertising-supported apps, I’d think again. Take a look at how many ad-supported apps Apple has featured in their commercials. In this case, if banning UDID tracking actually discourages advertising-supported applications, that may be something Apple wants. Ultimately, the handling of the UDID issue is the symptom, not the disease. Uncertainty in the App Store is bad for developers, businesses, industries and most importantly users, but there doesn’t seem to be a clear way for Apple to diminish that uncertainty that doesn’t also inhibit them from evolving iOS and reacting swiftly to the two-crises-per-year schedule Apple has been on. As long as the walled garden is up, people are going to want to trust the gatekeepers. Or think about it another way: the parent gets blamed when the child misbehaves. And when one child misbehaves, all the children get punished. UPDATED: This piece engendered enough discussion that I thought it was worth clarifying some points and adding some nuance that I failed to do earlier. On UDID, alternatives to, and tracking in general: Though UDID was just the latest issue, my point wasn’t about UDID. I simply used it as an example of a formerly allowable behavior that businesses depended on. In fact, I think Apple’s moves towards greater privacy have been well documented, as has Apple’s past behavior, but there still seems to be enough confusion about what their moves will actually mean for businesses that it was worth discussing again. More than that, I think that Apple is doing the right thing and could go even further, and may yet still, by more severely restricting cross-application sharing of user behavior. On iOS being a bad environment for developers or for users: Nope. As my points were directed to developers, let’s start there. iOS is largely the best environment for anyone trying to make money in mobile. It’s also where so many people are and are heading that it’s impossible to ignore. The risks I discussed above don’t change the tremendous opportunity of iOS. This is not a net-negative situation for most. But if you’re in mobile ads, it may very well be. As for users, iOS devices are still, in my opinion, the best devices out there. With regards to UDID, this is a situation that’s actually better for users. In cases where Apple rejected apps for duplicating existing functionality, that clearly isn’t the case. But overall Apple has shown sensitivity towards making things better for users. I don’t think the same can be said as confidently in their treatment of developers. On possible prescriptions to this problem: I don’t see any, which obviously doesn’t mean none exist. But for the next few years at least, further changes like this are a near-certainty, and developers will have to learn to live with it, which I don’t think they have yet. It’s simply a different type of risk that many are not accustomed to. Is the risk also greater than it was in the past for consumer web companies and services? Debatable, but I think it is as we move away from the browser and the web as a central mode of interaction with the Internet. The browser and the web had clearer behavioral standards than mobile environments do, and there are and were more efforts to establish those standards between platforms. Are behavioral standards going to become clearer in iOS? At some point, but that will happen because of one organization. EDIT: I did indeed mean Delphic instead of Solomonic in the first paragraph, as Sammy Lao pointed out in the comments. [Image via Rosser1954/Wikipedia]
  |
| Israeli-American Accelerator UpWest Labs Graduates Its First Batch Of Startups Posted: 29 Mar 2012 09:57 PM PDT  When it comes to countries with thriving startup ecosystems, Israel ranks among the best. With nearly 5,000 startups currently in business — second only to the U.S. — the country’s pool of entrepreneurial talent has been attracting Western businesses and entrepreneurs for years. But, in January, Gil Ben-Artzy and Shuly Galili launched a startup accelerator that aims to reverse this trend in favor of Israeli entrepreneurs, by bringing the country’s promising founders to Silicon Valley to help them kick start their businesses. And, today, after 10 weeks of mentoring, networking, and iterating, UpWest Labs is revealing the six graduates of its inaugural batch. As Eric pointed out last month, while Israel has a thriving startup community, challenges remain. The market is small (Israel is roughly the same size as New Jersey), and Israeli venture capital has been making a shift to focusing on late-stage investments. So focusing on early-stage businesses, gathered in small cohorts, is important to UpWest. Galili also tells us that UpWest is currently the only accelerator in the U.S. focused solely on Israeli startups. Of course, while its entrepreneurs are unique in that sense, UpWest is emulating the litany of accelerators and incubators that have popped up over the last few years, in the sense that it’s bringing entrepreneurs to its offices in Palo Alto, offering them housing in Menlo Park, access to a long list of local mentors, and is providing seed funding in the $15-20,000 range in exchange for up to 8 percent equity. Though its model may sound familiar, UpWest knows it has to differentiate if it wants to be around for any significant amount of time. So, as opposed to the traditional approach of accelerators, which generally focus on ambitious founders slinging tons of ideas, UpWest is focused on finding entrepreneurs who have already built products that have found some traction, so that they can use their time in Silicon Valley more effectively. UpWest also aims to keep its class size small in order to provide companies with maximum attention. After officially opening its doors in January, UpWest shortly thereafter welcomed its first class of entrepreneurs to the Valley. As a new generation of consumer-focused startups has emerged in Isreal over the last few years, UpWest is looking to build a valuable resource for this new set of companies tackling the consumer Web. Last week, the accelerator graduated its first-ever batch of startups, including mobile, social, gaming, and SaaS companies. Six startups are officially being released into the wild, and below we’re offering a glimpse into what makes them tick. Contapps is a universal contacts platform designed to help you connect, however you want, with the people you care about. The startup is operating under the assumption that the tools and networks we use to communicate all live in apps in our smartphones that are scattered all over our phone, so Contapps has built an app that puts contact info front and center. The “contacts platform” brings together free SMS, Facebook, Twitter, and more so that you can choose the best medium to reach out to your contacts — all in one place. The startup’s Android app has racked up over 500,000 downloads, and an average 4.4 star rating across 5,500+ reviews. OffScale is a database version management platform — or, in its own words, Git for databases — aimed at allowing businesses to focus on creating faster product development cycles and releases by taking the hassle out of copying and managing their databases. OffScale wants to help you organize and manage those snapshots you take of databases, including offering easy rollback, even if your database runs in a third-party cloud, as the software runs the same on your laptop and on the virtual server. The startup is also offering the ability to create and maintain datasets for automatic testing, along with the protection of being able to speedily tag and restore databases. Offscale is currently in beta, and while in beta, the software is free to download. Tradyo likens its used goods marketplace to a “StumbleUpon for tangible things.” The startup’s iPhone app enables users to buy and sell used goods in your area in realtime. The app uses GPS to reveal the cool stuff available around you, allowing you to sell an item, search your community for cool stuff, and receive push notifications when an item you want gets listed, or when someone wants to buy what you’ve listed. Like Antengo, Tradyo wants to improve upon the mobile Craigslist model in an attempt to make classifieds safe, easy, and realtime — in other words, leveraging the popularity of the collaborative consumption movement to re-imagine what it means to shop locally. Senexx is using its patent-pending technology to help enterprise organizations identify and manage expertise via an internal Q&A platform. The startup’s advanced parsing and knowledge-routing algorithms aim to reduce the amount of time it takes for employees to find answers or domain experts with specific knowledge in a particular subject within their company. This is complemented by the ability to catalog past solutions to certain events or situations — the overall goal being to streamline in-house expertise in order to more effectively deal with problems, or opportunities. The startup’s private, cloud-based service integrates into your company’s exiting enterprise networking platforms to allow it to take advantage of current collaboration systems, whether it be email, instant messaging, or internal social networks, in an effort to improve cross-team collaboration. To find out more about pricing, contact the founders here. Bfly is a “mobile experience” which enables users to connect to other people, locally and around the world, using a virtual, 3-D butterfly of all things. The startup is currently in private beta, and will be launching its iOS and Android mobile apps in the next few months. But from what we can tell, Bfly is almost like a mobile, virtual chain letter. Each user creates a unique virtual butterfly and passes it to a friend’s mobile device when they cross paths. According to Bfly, as the butterfly hops from one mobile devices to another, users can track its journey, view stats and photos taken by other users it meets as it goes. The startup is obviously looking to tap into the far-reaching potential of mobile technology to give users a fun, somewhat serendipitous, and quirky way to meet new people. Invi is currently in stealth mode, so the team isn’t saying much about its product, other than the fact that it is trying to reinvent SMS, and perhaps iMessage along the way, by building a next-gen texting app for mobile devices. If that piques your curiosity, you can sign up for the startup’s beta here.
  |
| Best Buy To Shut 50 Stores In Streamlining Effort Posted: 29 Mar 2012 07:41 PM PDT  TechCrunch’s Best Buy tag isn’t exactly a heartening place to visit. In the last few months, it “stole Christmas,” been “finished,” and is now “going out of business.” Dire straits indeed for a company that has defied the odds not only against big retail competition but against deadlier online opponents as well for nearly 50 years. But an announcement today seems to give a little weight to the doom and gloom expected from a tech community that views Best Buy as an anachronism. Best Buy will be closing 50 of its big box stores and laying off some 400 people, mostly on the administrative side. Is it rightsizing or just plain attrition? CEO Brian Dunn sees it as a necessary measure to reduce costs and make the chain’s retail experience more relevant to the average consumer. “We’re going to have more doors and less square footage,” he said, suggesting that further big box closures may be in the company’s future, but at the same time assuring that said closures were part of an overall strategy. The sprawling megastores cost far more and see more competition from the likes of Amazon and Newegg, whereas smaller stores with popular items and services save on both space and costs. One has to admit that it makes a certain amount of sense. Best Buy is in the retail business, not the warehousing business, and at any rate they can’t compete in the latter category with online storefronts. The 400 jobs, which Best Buy said would mostly come from its headquarters, would be enough to raise an eyebrow, but they neglect to estimate the real number of jobs that will be lost as a result of the closures. The employees of the 50 stores could easily amount to a couple thousand with floor staff, management, warehousing, and so on. Needless to say, it’s not a number they care to shout from the rooftops. It would take the wind out the sails just when the new plan needs a boost.
  |
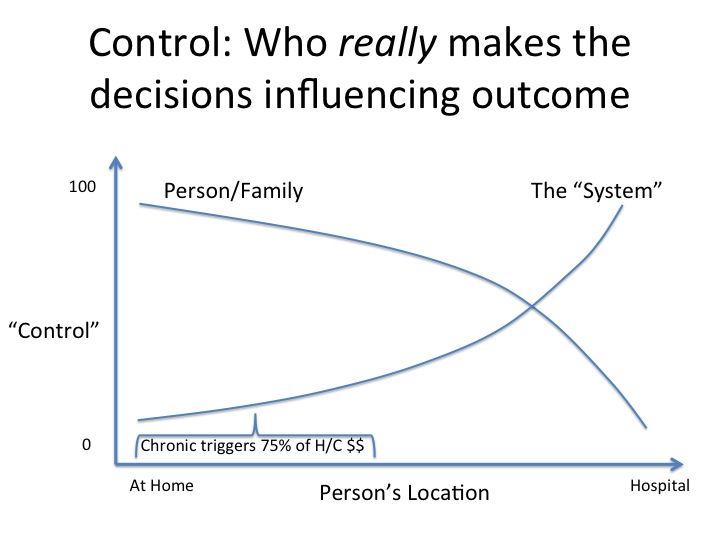
| Patients Are More Than A Vessel For Billing Codes Posted: 29 Mar 2012 07:00 PM PDT  Editor's note: This guest post was written by Dave Chase, the CEO of Avado.com, a patient portal & relationship management company that was a TechCrunch Disrupt finalist. Previously he was a management consultant for Accenture's healthcare practice and founder of Microsoft's Health platform business. You can follow him on Twitter @chasedave. It will be virtually impossible to succeed in the new reimbursement model without recognizing what has long been said, but little done about it — “the most important member of the care team is the patient.” Having implemented or reviewed over 100 health IT systems, there is one common purpose at the core of the architecture of these systems — how to get as big a bill out as quickly as possible. That has been an entirely rational response to the flawed reimbursement model at the heart of healthcare’s hyperinflation (here’s a not-so-fun fact: Since the ’60s, while all non-healthcare expenditures increased 8x, healthcare increased 274x). While there is much uncertainty about the future of healthcare, there is one certainty: healthcare will be paid based on some blend of value/quality/outcome and a shifting away from the “do more, bill more” reimbursement model. It’s hard to overstate the scale of this change and what it means for healthcare providers and the organizations that support them. This will make the shift from analog to digital media look trivial. One similarity to the analog-to-digital media shift, however, is healthcare will also face deflationary economics that will produce many winners and losers. It is also changing what has long been been said – healthcare is where tech startups go to die. Instead, there are exciting new opportunities exploding all around the healthcare continuum. The chart above speaks to the importance of the individual (or family member) in the care process. There are two curves. One is the degree to which the healthcare system is in control while the other is the degree to which the individual (aka patient) is in control. Clearly, when an individual is in a hospital — perhaps unconscious after an accident or during surgery — the healthcare system is in control (appropriately so) of the decisions that drive the outcome. In contrast, the situation is different when one is managing a chronic condition which represents roughly three-quarters of all healthcare spending. In those situations, it is the patient who is control. They decide whether they’ll fill prescriptions, take the pills, change exercise or diet habits and so on. Their actions will be the determinant of the outcome. Top health systems perform extraordinarily well when there is the medical equivalent of a big fire. However, it is individuals who are the key player in keeping small fires from growing bigger and fire prevention. Just speaking to the technology side of the equation, health systems have invested massive sums of money to fight the big “fires” that take place in hospitals. The opportunity for healthtech startups today is to develop the equivalent of CO2 alarms, fire extinguishers, keeping fires from reigniting, fire inspections, and better communication systems that snuff out small “fires” or prevent them from happening all together. Providers who’ve slayed the healthcare cost beast While single digit savings translate into big money in healthcare, there are a few organizations who have had double-digit cost reductions and outcome improvements. In earlier pieces, I have highlighted two organizations that have had impressive results by developing new care models.
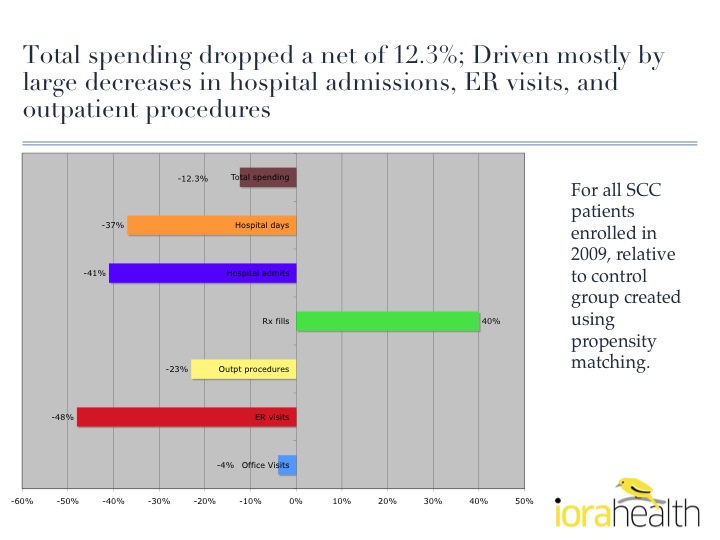
There are two others that have particularly demonstrated the importance of individuals and behavioral science. Their leaders are continually looking for ways to improve. As word spreads about their accomplishments, others are seeking to replicate their success. Iora Health’s Rushika Fernandopulle was highlighted in Atul Gawande’s famous “Hot Spotters” piece from the New Yorker. The graphic below demonstrates their results. Iora Health is one of the pioneers in the Direct Primary Care Medical Home movement and received $6.3M of funding recently. The SouthCentral Foundation in Alaska has demonstrated that it is possible to turn around a government-funded health system (Indian Health Service, Medicare & Medicaid provide 95% of their funds). Their “Nuka System of Care” is a great example of DIY Health Reform driven at the grassroots level. The core insight that has led to truly impressive outcomes has been that for 75% of healthcare spend (chronic disease management), it is the individual or their family who is in control of the decisions that drive outcomes. The graphic below depicts this. The video below is from Mark Begich (Representative from Alaska) describing the results of this model. If you are interested in an in-depth perspective, leaders from the SouthCentral Foundation explain how they do it in two parts. Some nominal efforts have been made to weave in the individual into the care process. Even simple secure messaging has been held up as a great breakthrough in medicine. I liken the limited efforts to invite the patient into the process to seeing a muddy puddle of water in the Sahara Desert — it’s a welcome improvement but far from optimal. The healthcare organizations that will not just survive, but will thrive, are recognizing that a tweak to a system that was designed around the patient as billing vessel won’t get the job done. As we’ve seen in many areas, tweaks to an architecture designed around a different model never succeed in the new paradigm. If they did, Yahoo or AOL would be the leaders in social media. Expect to see the equivalents of Facebook and Foursquare emerge in healthcare. Related articles:
  |
| Kickstarter Shares The Effects Of Its Blockbuster Season Posted: 29 Mar 2012 05:30 PM PDT  February was a big month for Kickstarter. Not only did they have a number of record-breaking projects, but they were shoved into the mainstream consciousness with a flood of traditional news coverage. But there was always the question of whether these thousands of pledges would have any lasting effect on the site. Could such a rush of attention actually have negative effects, increasing competition and bringing in more projects than the site’s population of donors can handle? Fortunately, that doesn’t seem to have been the case. The site’s big month appears to have made a lasting increase in both projects, users, and funding. There are a ton of details at Kickstarter’s blog post, but the gist is this: the two biggest projects lately, Double Fine Adventure and Order of the Stick, brought in millions of dollars themselves, but have also produced a halo of funding where there was very little before. In the gaming category, for instance, only one project had reached $100,000 in funding before last month. Since then nine have. And in webcomics, where the Order of the Stick book was categorized, the number of pledges per week, on average, has doubled. They’re not just staying in the original category, either: 22% of each group of original backers have been busy in other categories, backing nearly 2000 projects with over $1m all told. Many of the backers were on Kickstarter for the first time to back the big projects, and these big names on the marquee ended up working as advertisements for the site itself as well. It just goes to show that crowd-funding is a space with a ton of room to grow as new models and ideas are found to be applicable. Before last month, many would have thought that raising millions via Kickstarter was a fantasy. But the scale of the site is growing and naysayers are constant casualties. What remains to be seen is how long Kickstarter itself can remain on top. Just as it brought a change to the world of funding and launching products, another could bring yet more changes to the still-nascent field of crowd-funding.
  |
| Confirmed: LivingSocial Co-founder Eddie Frederick Steps Down From Leadership, Board Posted: 29 Mar 2012 05:14 PM PDT  StartupStats got wind of news this afternoon that LivingSocial Co-founder Eddie Frederick is stepping down from both his leadership position today, and from his role as a member of the company’s board of directors. We’ve since been able to confirm the news by way of LivingSocial Director of Communications Brendan Lewis. Frederick co-founded the daily deal giant back in 2007 with CEO Tim O’Shaughnessy, CIO Val Aleksenko, and CTO Aaron Batalion. The four met while working for Revolution Health, and, after completing work on the consumer healthcare portal, they decided to leave to pursue their already-launched Facebook app, Virtual Bookshelf. The book solution, formerly known as Hungry Machine, was initially the company’s flagship product, before it became the Groupon competitor we know today. Frederick spent the following year developing Facebook apps, among them Pick Your Five, which let users pick things they liked and write about them on their online profiles. In the beginning, LivingSocial fancied itself more of a general interest online social network, and it first started to really gain traction when Pick Your Five exploded (going from 0 to 35 million users in about three weeks). The following year, the company acquired Buy Your Friend A Drink, a company specializing in sending users to local bars to redeem drink vouchers, which eventually gave rise to LivingSocial Deals. From then until November 2011, Fredericks served as President of LivingSocial (at which point the company underwent a big shuffling of leadership titles) and on the company’s board of directors — and today he’s relinquishing both roles. It is not clear as of now what Frederick will be doing next, or whether or not he will be selling his stake in the company — or whether or not this has anything to do with with LivingSocial’s reported IPO. But we have heard from sources close to the company that this was an “amiable departure.” The company’s spokesmen declined to comment about the IPO rumors, but, the company raised a sizable $176 million series F round in December (with the total offering amount being $400 million), bringing its current total investment to $808 million. At the time, Erick speculated that this new infusion of private capital (at a reported $6 billion valuation), would potentially allow it to avoid those IPO fees and continue to grow organically, focusing on talent and strategic acquisitions, among other things. The company has certainly been focusing on the latter, as an updated filing with the SEC from Amazon — which owns a 31 percent stake in LivingSocial — revealed that the company sustained $558 million in losses in 2011, emanating largely from acquisitions, stock compensations, and marketing costs. While this was an expected result of the daily deal site’s fast-paced growth cycle, it still took many by surprise. LivingSocial also announced today that LivingSocial Instant, its product designed to allow restaurants to offer flash discounts to customers during hours of slow traffic, would be shutting down. Instant is to be replaced by a food-ordering service called “Takeout & Delivery.” As to the news of Fredericks stepping down, Nick O’Neill of StartupStats was able to obtain the email from LivingSocial CEO Tim O'Shaughnessy, which announced the co-founder’s departure. An excerpt is below, and you can find the full email here.
We’ve reached out to Eddie and others, who as of now, could not be reached for comment, but we’ll update when we learn more. Image credit: Thais Luporini of SocialCash
  |
| Posted: 29 Mar 2012 05:00 PM PDT  Editor’s note: Mark Kaganovich is founder of SolveBio and a doctoral candidate in genetics at Stanford University. Follow him on Twitter @markkaganovich. Much ink has been spilled on the huge leaps in communications, social networking, and commerce that have resulted from impressive gains in IT and processing power over the last 30 years. However, relatively little has been said about how computing power is about to impact our lives in the biggest way yet: Health. Two things are happening in parallel: technology to collect biological data is taking off and computing is becoming massively scalable. The combination of the two is about to revolutionize health care. Understanding disease and how to treat it requires a deep knowledge of human biology and what goes wrong in diseased cells. Up until now this has meant that scientists do experiments, read papers, and go to seminars to get data to build models of both normal and diseased cell states. However, medical research is about to go through a tectonic shift made possible by new technological breakthroughs that have made data collection much more scalable. Large amounts of data combined with computers mean that researchers will have access to data beyond just what they can themselves collect or remember. A world with affordable massive data in the clinic and in the lab is on the horizon. This will mean exponentially faster medical progress. New technology is changing research A major challenge thus far has been the difficulty in gaining access to clinical data. Observational studies have had limited success because collecting enough meaningful data has not been possible. For research to move faster human clinical data must be collected and integrated to yield actionable results, by universities, hospitals, and biotech companies. Developments in biotechnology over the last 10 years are painting a picture of how the new world of "Big Bio" might come into existence. Rapidly improving scale and accuracy of DNA sequencing has led to leaps in our understanding of genetics. This is just the beginning – sequencing technology is still very much in development. There are three publically traded companies, and about a dozen high profile startups/acquired startups whose entire business is the race for faster, cheaper, more accurate sequencing. At this point, clinical applications are usually limited to screens for known genetic markers of disease or drug response, but as the cost of data acquisition drops we will start to see companies and academics use unbiased observational correlations to generate meaningful hypotheses about the genetic causes of disease. Sequencing is one of many technologies experiencing a revolution in accuracy and scale. Progress is being made in imaging and identifying proteins, metabolites, and other small molecules in the body. The result is the opportunity to create pools of comprehensive data for patients and healthy people where researchers can integrate data and find patterns. We simply haven't had anything like this before. Patients can measure every feature, as the technology becomes cheaper: genome sequence, gene expression in every accessible tissue, chromatin state, small molecules and metabolites, indigenous microbes, pathogens, etc. These data pools can be created by anyone who has the consent of the patients: universities, hospitals, or companies. The resulting networks, the "data tornado", will be huge. This will be a huge amount of data and a huge opportunity to use statistical learning for medicine. It could also create the next engine of economic growth and improve peoples' lives. The question remains how will all this data be integrated. The missing piece of the puzzle is the parallel advancement we've seen in the past 6 years in cloud computing. Correlation in the cloud The cloud will make data integration possible, useful, and fast as new types of data appear. Data and algorithms can be distributed to people who specialize in different fields. The cloud can help create a value network where researchers, doctors, and entrepreneurs specializing in certain kinds of data gathering and interpretation can interface effectively and meaningfully. The true value of the data will begin to be unlocked as it is analyzed in the context of all the other available data, whether in public clouds or private, secure silos. This massively integrated analysis will speed the transition from bleeding edge experimentation to standards as solutions and data interpretations move from early-adopter stage to the good-enough stage where they will compete on ease-of-use, speed, and cost. SolveBio, my startup, is working on making it better and easier to run large-scale analysis apps and data integration tools by taking advantage of bleeding edge cloud computing. The result will finally be literal exponential growth in medical knowledge in the sense that new medical discoveries will benefit further discovery. The results of research will create clinical demand that will be fed back into the data tornado for analysis. A key area that is likely to be the first to benefit from massively distributed data integration technology is cancer research. At some point you will get cancer if you live long enough because cancer is a disease of genetic regulation going wrong. The thing that makes it complicated is that cancers result from many different things going wrong in different cells. For complex diseases, lumping cases together into a few linguistic terms doesn't reflect the biology: we have classifications like asthma, autism, diabetes, and lymphoma, but the reality is that each pathology is probably significantly different among individuals on dimensions that can be relevant to therapy. As Clay Christensen and colleagues point out in Innovator's Prescription, there used to be 2 types of "blood cancer" and now physicians classify 89 types of leukemias and lymphomas. The reality is probably that there are N types of lymphomas, where N is the number of people who have lymphoma. Cancer research = Big Bio Cancer is the ultimate Big Bio problem. Tumors may have millions of mutations and rearrangements as compared to normal tissue in the same individual, and cancer cells within the tumor itself may have different genomes. Most of the mutations may be uninformative "passengers" that come along for the ride, whereas many might be "drivers" that actually cause the unregulated cell proliferation that defines cancer. To distinguish between "drivers" and "passengers" very many cases and controls are needed to understand which mutations repeatedly appear in cancerous, but not normal cells. Collecting comprehensive profiles of every tumor for every patient provides a dataset to build models that learn normal cellular function from cancerous deviations. Diagnostics and treatment companies/hospitals/physicians can then use the models to deliver therapy. If we imagine a world where every tumor is comprehensively profiled, it quickly becomes clear that not only will the data sets be very large but also involve different domains of expertise required for quality control, model building, and interpretation. Every cancer and person will be different based on their genome, proteome, metabolite and small molecule profiles, and features we have yet to discover. Stratifying by every possible relevant dimension to build the best models of effective drug targets and treatment regiments is a massive computational task. With current technology it takes a 16GB RAM desktop about 2 days to process gene expression data. If a biotech is analyzing a couple thousand patients, with 10 time points, and a few cancer samples each time, that quickly adds up to 570 years on the desktop. This is just gene expression profiling, and doesn't take into account the downstream data integration analysis to find informative correlations. Only a distributed computing platform can get the job done, and the cloud opens this work up to the masses. We are catching a glimpse of how just DNA sequencing and computation can contribute to the transformation of oncology from the realm of Intuitive Medicine to Precision Medicine (to borrow from Clay Christensen, again). A major first step is to better target therapies based on genetics. It is estimated that only one-fourth of administered chemotherapy drugs have their intentional cytotoxic effect. Herceptin (Genentech) was the first cancer drug to actually come with a genetic test: it targets tumors specifically over-expressing one gene. Many more are in the pipeline, and Foundation Medicine is working on ways to better inform doctors and pharma companies as to how to target new drugs based on gene sequencing. Numedii is using genomic profiling to reposition drug compounds already approved by the FDA. Champions Oncology can graft your tumor onto a mouse and test drugs there. Big Bio in Cancer research has game-changing implications for treatment and diagnosis. As other types of data are measured for cancer cells we will learn more and more from data integration. The cloud can seriously help treat cancers by allowing researchers, doctors, and engineers gather, interpret, and integrate data on unprecedented scales. As we begin to understand more precisely how individual cancers work, drug development ventures will have a much better sense of what to focus on, diagnostics companies will know what to look for, and patients will be treated by therapies that maximize effectiveness and minimize side effects – all based on actual data. [image from Moneyball]
  |
| WSJ: Google Planning To Sell Tablets Straight To Consumers Posted: 29 Mar 2012 04:43 PM PDT  Here we go again: the rumors of Google branching out into the tablet space have been floating around for what seems like ages now, and the Wall Street Journal has jumped into the fray. They cite the usual handful of unnamed sources, who this time say that Google is planning to open up their own online store à la Amazon to sell Android tablets. Not just any Android tablets, mind you — co-branded ones that bear Google’s name along with that of the manufacturer. Google does many things (some better than others), but they’re definitely not in the consumer hardware production game. Instead, Google is said to be working with hardware experts at Asus and Samsung (and presumably Motorola at some point), and is also considering the possibility of subsidizing the tablet’s price to fall in line with devices like Amazon’s Kindle Fire. If these whispers hold true, then Google could be onto something. That theoretical store could already have a flagship if the oft-rumored $199 Nexus Tablet actually materializes, and the package only gets sweeter if it ends up running Jelly Bean, which the WSJ reports will hit in mid-2012. To date, the only Android tablet to give the iPad a run for its money is the Fire, but if Google can get close in price while beating them out on specs, Amazon could be in trouble. The formula may not exactly prove to be an iPad killer, but a strong second place in the tablet race is nothing to sneeze at. What gets me though is how Google is reportedly thinking of selling these things. Google has toyed with this sort of online retail model before — the Nexus One was sold unsubsidized by Google, even though T-Mobile provided the network for it. By the time Google’s next Nexus made the rounds though, the search giant wised up and tapped Best Buy to help put the Nexus S into people’s hungry hands. Getting those tablets out into meatspace could do wonders for visibility, and brick and mortar retail certainly has a sense of immediacy about it — there’s little delay between seeing something you want and owning it. Still, the direct-to-consumer approach has its advantages. By cutting out the retail middleman, Google gets to retain that much more control over the situation (not to mention the revenue they don’t have to share with stores). The Nexus One seems like a dicey precedent, but people who shied away from it didn’t do so because it was a bad phone, they did so because it was $529.99 without a contract. With potentially aggressively priced tablets and a decent payments system in tow, Google should be able to lock up this new revenue stream pretty tightly. That is, of course, if they can keep on top of demand for a cheap, Google-approved tablet.
  |
| Algorithmic Essay-Grading: Teacher’s Savior Or Bane Of Learning? Posted: 29 Mar 2012 04:30 PM PDT  A contest is underway at data-crunching competition site Kaggle that challenges people to create “an automated scoring algorithm for student-written essays.” This is just the latest chapter in a generations-long conflict over the nature of teaching, and to that end it’s also just one of many inevitable steps along the line. Automated grading is already prevalent in simpler tasks like multiple-choice and math testing, but computers have yet to seriously put a dent in the most time-consuming of grading tasks: essays. Millions of students write dozens of essays every year, and teachers will often take home hundreds to read at a time. In addition to loading the teachers with frequently undocumented work hours, it’s simply difficult to grade consistently and fairly. Are robo-readers the answer? Mark Shermis at the University of Akron thinks it’s at least worth a shot. The competition is structured as you might expect, and actually is nearing its conclusion. It’s been ongoing for a few months and ends on April 30th. So far there are over 150 entrants and over 1,000 submissions. The contest provides them with a database of essays and their scores to “train” the engines, then tests them, naturally, on a new set of essays without scores. Presumably the engine that produces the most reliably human-like results will take home the first prize: $60,000. Then it’s $30k for second place and $10k for third. The contest is sponsored by the William and Flora Hewlett Foundation. It’s interesting enough as a data-analysis project, but likely also to be a major point of contention over the next decade or so. The increasing systematization of education is something many teachers and parents decry; the emphasis on standardized tests is abhorrent to many, while the human component of essay grading is considered indispensable. To replace human readers with robots – “It’s horrifying,” says Harvard College Writing Program director Thomas Jehn, speaking to Reuters. “I like to know I’m writing for a real flesh-and-blood reader who is excited by the words on the page. I’m sure children feel the same way.” Fair enough. But if the results are the same, is there really a conflict? Ideally, these machine readers would produce the same grade, for the same reasons. Is a TA scanning each essay and marking off the salient key words and checking for obvious failures doing a better job? It probably depends on the TA. And the professor or teacher, and the student, the length and topic of the essay, and so on. There’s a counter-argument, then, that grading essays is, much of the time, a mechanical process that humans have to perform, and which in many cases they can’t perform consistently. Like working at an assembly line — a robot can do it faster and cheaper. This has real benefits, not least of which is freeing the humans to do more human work. TAs could spend more time doing one-on-one tutoring, and teachers could work harder on lesson plans and the actual process of teaching. The essay-grading portion is only “phase one” of the project’s plan, though. Phase two would focus on shorter answers, and phase three on charts, graphs, representations of math and logic. It’s exciting, but it’s one of those areas of advancement that makes many uncomfortable. It could be said, though, that we feel uncomfortable because it is those very areas that need the most attention.
  |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| You are subscribed to email updates from TechCrunch To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |
Hii you are providing good information.Thanks for sharing AND Data Scientist Course in Hyderabad, Data Analytics Courses,
ReplyDeleteData Science Courses, Business Analytics Training ISB HYD Trained Faculty with 10 yrs of Exp See below link
Data Scientist Course In Hyderabad